
GitHub actions is a (relatively) novel GitHub feature that allows you to run code on GitHub when a predefined event is triggered. The most widespread use case for GitHub actions is for Continuous Integration, because it allows you to automatically test your code on any machine immediately after each push. For a great tutorial on how to use it for this see here.
But you can do so much more with them!! Basically you can set up any workflow to run after any event. An event is basically when a specific activity on GitHub happens, while a workflow is basically the script you want to run after the event has happened. For a full list of the events you can use see here. Workflow scripts are written in a .yml file and should be saved within the .github/worflows directory within your repository. I am incapable of writing a better tutorial for these than what is already on their documentation, but I will show a copy of a workflow script I recently put together and walk you through it.
In one of my previous blog posts I wrote about how to upload your code to PyPI. Hopefully I convinced you that this is quite easy, but it does require a few steps that you may not want to be doing every time you come up with a new feature (find a bug) and have to re-upload it. Luckily, you don’t have to!! Just stick the code into a GitHub actions workflow so it will automatically re-upload it for you. Here is the script I use for this:
Continue reading
 into two sets – a training set
into two sets – a training set 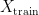 and a test set
and a test set 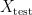 . The model is then subsequently trained on the examples in the training set
. The model is then subsequently trained on the examples in the training set 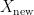 which it will encounter in the future. Right?
which it will encounter in the future. Right?