In the first meeting of the OPIG Algotirhm Club, we tackled the problem 3n+1 from the Sphere Online Judge (SPOJ).
—Background —
The problem relates to the Collatz conjecture. Before describing the conjecture, let us define a very simple recursive relation:
- If a number is odd, multiply it by 3 and add 1 (hence 3n+1).
- If a number is even, divide it by 2.
The Collatz conjecture states that for any given integer, you can repeat this recursion indefinetely and you will always reach the number 1.
The 3n+1 problem requires yet another concept which is the cycle length (i.e. the number of times you have to repeat the recursion for a given number until you reach 1).
— Goal —
The aim of the problem is: given 2 integers i and j, find the number with the highest cycle length that lies in the interval comprised between the 2 integers (them included).
— Important Issues —
Two things are worth mentioning before attempting to implement this problem:
- i could be either greater than or lesser than j.
- Despite the fact that the description of the problem states that all operations can be performed using int, there are certain inputs between 100,000 and 1,000,000 that violate that statement.
— Implementation —
A simple solution can be implemented by using a recursive function to compute the cycle length:
int Cycle_Length (unsigned int n) /* Note the unsigned precision */
{
unsigned int aux;
/* Stopping Condition - Don't want the recursion to run for forever */
if (n == 1) return 1;
/* Here is the recursion, if n is odd else if n is even */
aux = (n%2) ? (1 + Cycle_Length(3*n+1) ) : (1+Cycle_Length(n>>1));
/* Note that division by two is performed by shifitng a bit to the right */
return aux;
}
Now, there are two ways we can optimise this function and make it more efficient.
The first one relates to a certain property of odd numbers: we know that if n is odd, than 3*n+1 is going to be even. Therefore we can simply skip one iteration of the cycle:
aux = (n%2) ? (2+Cycle_Length((3*n+1)>>1)) : (1+Cycle_Length(n>>1)) ;
We can further optimise our code by using Dynamic Programming. We can store the Cycle Lengths we already computed so we don’t need to compute them ever again.
Using dynamic programming and the tricks above, we can get to the final solution (which runs pretty fast on the Online Judge platform):
#include<stdio.h>
#include<stdlib.h>
int CycleLength[100001];
int Cycle_Length (unsigned int n)
{
int aux;
if(n>100000)
{
aux = (n%2) ? (2+Cycle_Length((3*n+1)>>1)) : (1+Cycle_Length(n>>1)) ;
return aux;
}
if(!CycleLength[n])
CycleLength[n] = (n%2) ? (2+Cycle_Length((3*n+1)>>1)) : (1+Cycle_Length(n>>1)) ;
return CycleLength[n];
}
int findmax(int a, int b)
{
int max=0,aux,i;
for(i=a;i<=b;i++)
{
aux=Cycle_Length(i);
if(max<aux)
max=aux;
}
return max;
}
int main()
{
int a,b;
CycleLength[1]=1;
while(scanf("%d %d",&a,&b)!=EOF)
a<b?printf("%d %d %d\n",a,b,findmax(a,b)):printf("%d %d %d\n",a,b,findmax(b,a));
return 0;
}
Ta daam!


 into two sets – a training set
into two sets – a training set 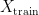 and a test set
and a test set 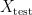 . The model is then subsequently trained on the examples in the training set
. The model is then subsequently trained on the examples in the training set 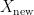 which it will encounter in the future. Right?
which it will encounter in the future. Right?