
Catherine’s Selection
Network approach integrates 3D structural and sequence data to improve protein structural comparison
Why: Current graph mapping in protein structural comparison ignores sequence order of residues. Residues distant in sequence but close in 3D space are more important.
How: Introduce sequence order of residues, set a sequence-distance cutoff to consider structurally important residues, count the graphlet frequency and embed into PCA space.
Results: the new method is predictive of SCOP and CATH ‘groups’. Certain graphlets are enriched in alpha and beta folds.
Link: https://www.nature.com/articles/s41598-017-14411-y
Investigating the molecular determinants of Ebola virus pathogenicity
Why: Reston virus is the only Ebola virus that is not pathogenic to human
What they do: multiple sequence alignment to look for specificity determining positions (SDPs) using s3det, then predict the effect of each individual SDP on the stability of the protein with mCSM.
Results: VP40 SDPs alter octamer formation, structure hydrophobic core. VP24 SDPs leads to impair binding to KPNA5 in human, which inhibits interferon signalling.
Impact: only a few SDPs distinguish Reston VP24 from VP24 of others. Human-pathogenic Reston viruses may emerge.
Link: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5558184/#__ffn_sectitle
Computational Analysis Highlights Key Molecular Interactions and Conformational Flexibility of a New Epitope on the Malaria Circumsporozoite Protein and Paves the Way for Vaccine Design
Why: An antibody with a strong binding affinity was found in a group of subjects. This antibody prevents cleavage of the surface protein.
What they do: They found the linear epitope, crystallise the strong and medium binders and run a molecular dynamic simulation to find out the flexibility of the structures.
Results: The strong binder is less flexible. Moreover, the strong binder is similar to the germline sequence which may mean that this antibody could have been readily formed.
Link: https://www.nature.com/articles/nm.4512
—
Matt’s Selection
“Analysis of sequence and structure data to understand nanobody architectures and antigen interactions”
Laura S. Mitchell (Colwell Group)
University of Cambridge, UK
This poster detailed the work from Laura’s two most recent publications, which can be found here: https://doi.org/10.1002/prot.25497, https://doi.org/10.1093/protein/gzy017
They describe a comprehensive analysis of the binding properties of the 156 non-redundant nanobody-antigen (Nb-Ag) complexes in the PDB/SAbDab (October 2017). Their analyses include Nb sequence variability (both global and across the binding regions), contact maps of nanobody-antigen interactions by region, and the typical chemical properties of each paratope. Nb-Ag complexes are compared to a reference set of monoclonal antibody-antigen (mAb-Ag) complexes. This work is a key first step in advancing our understanding of Nb paratopes, and will aid the development of new diagnostics and therapeutics.
“OSPREY 3.0: Open-Source Protein Redesign for You, with Powerful New Features”
Jeffrey W. Martin (Donald Group)
Duke University, USA
OSPREY 3.0 (https://www.biorxiv.org/content/early/2018/04/23/306324) represents a large advance towards time-efficient continuous flexibility modelling of protein-protein interfaces.
Its new algorithms LUTE and BBK* allow for continuous rotamer flexibility searching and entropy-aware binding constant approximation in a much more efficient manner. The CATS algorithm also introduces local backbone flexibility as a long-awaited feature. This software now has a easy-to-use Python interface, and is fully Open-Source, making it an extremely attractive alternative to other proprietary protein design tools.
“Functional annotation of chemical libraries across diverse biological processes”
Scott Simpkins
University of Minnesota-Twin Cities, USA
This interesting talk detailed the work published in Nature Chemical Biology in September 2017 (https://doi.org/10.1038/nchembio.2436).
310 yeast gene-deletion mutants were isolated to perform chemical-genetic profile studies across six diverse small molecule high-throughput screening libraries. By studying which gene-deletion mutants were hypersensitive or resistant to each compound, the researchers could assign most members of each chemical library a probable functional annotation. Mapping back to gene-interaction profile data also allowed them to infer likely targets for some compounds. The GO annotations associated with these genes could then be used assess whether a given starting library is likely to contain promising starting-points that affect a given biological function. For example, the authors highlighted a deficiency across all libraries against the cellular processes of cytokinesis and ribosome biogenesis. Conversely, they found a large enrichment across all libraries for compounds likely to affect glycosylation or cell wall biogenesis. Compounds that target transcription and chromatin organisation were found to be enriched in certain datasets, and depleted in others. This genre of profiling provides researchers a way of judging a priori whether a given screening library is likely to contain promising lead compounds, given the functional role of the target of interest.
 . However this assumption is often violated in virtual screening. For example, a chemist initially focuses on a series of compounds and the information from this series is used to train a model. For some reasons, the chemist changes their focus on a new, structurally distinct series later on and we would not expect the model to accurately predict the labels in the testing sets. Here, we introduce some methods to address this problem.
. However this assumption is often violated in virtual screening. For example, a chemist initially focuses on a series of compounds and the information from this series is used to train a model. For some reasons, the chemist changes their focus on a new, structurally distinct series later on and we would not expect the model to accurately predict the labels in the testing sets. Here, we introduce some methods to address this problem.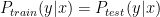 and
and 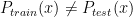 . In general, these methods reweight instances in the training data so that the distribution of training instances is more closely aligned with the distribution of instances in the testing set. The appropriate importance weighting factor
. In general, these methods reweight instances in the training data so that the distribution of training instances is more closely aligned with the distribution of instances in the testing set. The appropriate importance weighting factor  for each instance x in the training set is:
for each instance x in the training set is:
 is the training set density and
is the training set density and  is the testing set density. Note that only the feature vector values (not their labels) are used in reweighting. The major difference between KMM and KLIEP is the objective function: KLIEP is based on the minimisation of the Kullback-Leibler divergence while KMM is based on the minimisation of Maximum Mean Discrepancy (MMD). For more detail, please see reference.
is the testing set density. Note that only the feature vector values (not their labels) are used in reweighting. The major difference between KMM and KLIEP is the objective function: KLIEP is based on the minimisation of the Kullback-Leibler divergence while KMM is based on the minimisation of Maximum Mean Discrepancy (MMD). For more detail, please see reference.



































{kind=link}