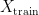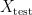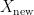The ability to successfully apply previously acquired knowledge to novel and unfamiliar situations is one of the main hallmarks of successful learning and general intelligence. This capability to effectively generalise is amongst the most desirable properties a prediction model (or a mind, for that matter) can have.
In supervised machine learning, the standard way to evaluate the generalisation power of a prediction model for a given task is to randomly split the whole available data set into two sets – a training set and a test set . The model is then subsequently trained on the examples in the training set and afterwards its prediction abilities are measured on the untouched examples in the test set via a suitable performance metric.
Since in this scenario the model has never seen any of the examples in during training, its performance on must be indicative of its performance on novel data which it will encounter in the future. Right?
Have you ever worked with a piece of software that is awfully difficult to set up? That legacy code written on FORTRAN 77, that other one that requires significant modifications to compile, or any of those that require a long-winded bash script with a thousand dependencies (which you also have to install!). Would it not be helpful if, when that red-eyed PhD student, that one that just spent three months writing up their thesis, says that they absolutely must use that server where you have installed all your stuff, you could just relocate to another one without trouble? Well, you may be able to do that now. You just need to use containerization.
The idea behind containerization is rather simple. The best way to ensure anyone can reproduce your work is to, well, ship your entire system to whomever needs to use it. You could, for example, pack up your desktop in a box, and ship it to your collaborators anywhere in the world. Unfortunately, this idea is quite unpractical, not only because of tedious logistics (ever had to deal with customs?), but also because suddenly you won’t be able to run your own pipeline. However, it is a good enough thought that at some point made a clever engineer wonder whether there was a way to ship an entire system without physically delivering the computer. And that’s exactly what they designed.
Best way to make sure your collaborators on the other side of the world can run your pipeline — just pack your desktop in one of these, and ship it away!Continue reading →
In preparation for remote teaching this year, I’ve spent the last few weeks converting the Doctoral Training Centre’s ‘Introduction to Computer Programming’ course into a series of Jupyter notebooks so that the course can be run entirely using Google Colaboratory.
Both the beauty and the downfall of learning-based methods is that the data used for training will largely determine the quality of any model or system.
While there have been numerous algorithmic advances in recent years, the most successful applications of machine learning have been in areas where either (i) you can generate your own data in a fully understood environment (e.g. AlphaGo/AlphaZero), or (ii) data is so abundant that you’re essentially training on “everything” (e.g. GPT2/3, CNNs trained on ImageNet).
This covers only a narrow range of applications, with most data not falling into one of these two categories. Unfortunately, when this is true (and even sometimes when you are in one of those rare cases) your data is almost certainly biased – you just may or may not know it.
Scientific code is never fast enough. We need the results of that simulation before that pressing deadline, or that meeting with our advisor. Computational resources are scarce, and competition for a spot in the computing nodes (cough, cough) can be tiresome. We need to squeeze every ounce of performance. And we need to do it with as little effort as possible.
Docker is an excellent containerisation system ideally suited to production servers. It allows you to do one small thing but do it well. For example, breaking a large blog up into individually maintained containers for a web-server, a database and (say) a wordpress instance. However due to inherent security woes, Docker doesn’t play nicely with multi-tenanted machines, the kind which are the bread and butter for researchers and HPC users. That’s where Singularity steps in.
Any opportunity to use rigorously tested and supported analysis tools rather than in-house code is, in my opinion, an opportunity you owe it to yourself to explore.
My preferred tool for analyzing the output of molecular dynamics (MD) simulations is MDAnalysis, a Python library that provides robust and easy-to-use tools for analyzing most common files output by MD packages (including PDB, DCD, COR, and XTC file formats). But, of course, MDAnalysis can analyze any PDB file, not just one output from an MD simulations. There may be an opportunity in your workflow to incorporate MDAnalysis to save time or to provide more robust error handling than whatever in-house code you currently use.
Most scientists working in the biological sciences or an overlapping field have encountered various ways of identifying genes and proteins. There are many different types of identifiers. For example, searching for the PDB ID: 2IW3 (which represents elongation factor 3 in yeast strain S288C) on UniProt gives us a results column labeled “Gene names” that includes no less than six (!) ways to refer to the gene that produces this particular protein. This can be frustrating – it is easy to get into trouble when you think you have a consistent gene naming scheme when you do not, especially if you want to cross-reference gene lists.
Jaffa cakes are God’s own snacks and I will brook no opposition. I don’t mind if they’re McVitie’s brand Jaffa cakes, or Pim’s, the suspicious European variety. Even Sainsbury’s Basics Jaffa cakes float my balloon. Take a soft sponge base, slap some jam and chocolate on that puppy, and you’re golden.
But if you describe your love of these glorious creations, the conversation takes a familiar turn. Are they cakes or are they biscuits? it goes. HMRC tried to classify them as cakes – or was it biscuits? Something like that. It had to do with VAT…
One could easily find dozens of reasons for which UNIX — mainly Ubuntu — is simply, the best operating system. Although I remember people in my proximity mentioning this for ages, it’s been only a few months that I’ve realized what are the true advantages. Helpful for this were all the people teaching/demonstrating in various modules during my first year in SABS/DTC: quite often we would be asked to do something in the console rather than by clicking the mouse. In the meanwhile, I’d wonder why using the console can be better from a nice, user-friendly GUI (i.e. Windows…). Tools like sed, grep,tar and of course alias-ing form a quick answer. I will not argue more about these but demonstrate two more tools/tricks.