
After my posts on how to turn a SMILES string into a molecular graph and how to turn a SMILES string into a vector of molecular descriptors I now complete this series by illustrating how to turn the SMILES string of a molecular compound into an extended-connectivity fingerprint (ECFP).
ECFPs were originally described in a 2010 article of Rogers and Hahn [1] and still belong to the most popular and efficient methods to turn a molecule into an informative vectorial representation for downstream machine learning tasks. The ECFP-algorithm is dependent on two predefined hyperparameters: the fingerprint-length L and the maximum radius R. An ECFP of length L takes the form of an L-dimensional bitvector containing only 0s and 1s. Each component of an ECFP indicates the presence or absence of a particular circular substructure in the input compound. Each circular substructure has a center atom and a radius that determines its size. The hyperparameter R defines the maximum radius of any circular substructure whose presence or absence is indicated in the ECFP. Circular substructures for a central nitrogen atom in an example compound are depicted in the image below.



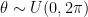 . Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution
. Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution 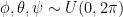 . This, however, gives more probability density to transformations which are clustered towards the poles:
. This, however, gives more probability density to transformations which are clustered towards the poles: