
Deep convolutional neural networks have lead to astonishing breakthroughs in the area of computer vision in recent years. The reason for the extraordinary performance of convolutional architectures in the image domain is their strong ability to extract informative high-level features from visual data. For prediction tasks on images, this has lead to superhuman performance in a variety of applications and to an almost universal shift from classical feature engineering to differentiable feature learning.
Unfortunately, the picture is not quite as rosy yet in the area of molecular machine learning. Feature learning techniques which operate directly on raw molecular graphs without intermediate feature-engineering steps have only emerged in the last few years in the form of graph neural networks (GNNs). GNNs, however, still have not managed to definitively outcompete and replace more classical non-differentiable molecular representation methods such as extended-connectivity fingerprints (ECFPs). There is an increasing awareness in the computational chemistry community that GNNs have not quite lived up to the initial hype and still suffer from a number of technical limitations.
Continue reading

 into two sets – a training set
into two sets – a training set 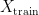 and a test set
and a test set 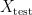 . The model is then subsequently trained on the examples in the training set
. The model is then subsequently trained on the examples in the training set 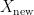 which it will encounter in the future. Right?
which it will encounter in the future. Right?

