
I’m dedicating this blog post to something I spend a great deal of my time doing – reading the manuscripts that members of OPIG produce.
As every member of OPIG knows we often go through a very large number of drafts as I inexpertly attempt to pull the paper into a shape that I think is acceptable.
When I was a student I was not known for my ability to write, in fact I would say the opposite was probably true. Writing a paper is a skill that needs to be learnt and just like giving talks everyone needs to find their own style.
Before you write or type anything, remember that a good paper starts with researching how your work fits into existing literature. The next step is to craft a compelling story, whilst remembering to tailor your message to your intended audience.
There are many excellent websites/blogs/articles/books advising how to write a good paper so I am not going to attempt a full guide instead here are a few things to keep in mind.
- Have one story not more than one and not less – when you write the paper look at every word/image to see how it helps to deliver your main message.
- Once you know your key message it is often easiest to not write the paper in the order the sections appear! Creating the figures from the results first helps to structure the whole paper, then you can move on to methods, then write the results and discussion, then the conclusion, followed by the introduction, finishing up with the abstract and title.
- Always place your work in the context of what has already been done, what makes your work significant or original.
- Keep a consistent order – the order in which ideas come in the abstract should also be the same in the introduction, the methods, the results, the discussion etc.
- A paper should have a logical flow. In each paragraph, the first sentence defines context, the body is the new information, the last sentence is the take-home message/conclusion. The whole paper builds in the same way from the introduction setting the context, through the results which give the content, to the discussion’s conclusion.
- Papers don’t need cliff hangers – main results/conclusions should be clear in the abstract.
- State your case with confidence.
- Papers don’t need to be written in a dry/technical style…
- …..but remove the hyperbole. Any claims should be backed up by the evidence in the paper.
- Get other people to read your work – their comments will help you (and unless it’s me you can always ignore their suggestions!)
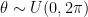 . Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution
. Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution 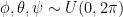 . This, however, gives more probability density to transformations which are clustered towards the poles:
. This, however, gives more probability density to transformations which are clustered towards the poles:

