
The ability to successfully apply previously acquired knowledge to novel and unfamiliar situations is one of the main hallmarks of successful learning and general intelligence. This capability to effectively generalise is amongst the most desirable properties a prediction model (or a mind, for that matter) can have.
In supervised machine learning, the standard way to evaluate the generalisation power of a prediction model for a given task is to randomly split the whole available data set 
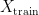
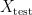
Since in this scenario the model has never seen any of the examples in 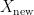



{kind=link}