Some molecular pose generation methods benefit from an energy relaxation post-processing step.

Here is a quick way to do this using OpenMM via a short script I prepared:
Continue reading
Some molecular pose generation methods benefit from an energy relaxation post-processing step.
Here is a quick way to do this using OpenMM via a short script I prepared:
Continue readingOne of the most annoying parts of ML research is keeping track of all the various different experiments you’re running – quickly changing and keeping track of changes to your model, data or hyper-parameters can turn into an organisational nightmare. I’m normally a fan of avoiding too many different libraries/frameworks as they often break down if you to do anything even a little bit custom and days are often wasted trying to adapt yourself to a new framework or adapt the framework to you. However, my last codebase ended up straying pretty far into the chaotic side of things so I thought it might be worth trying something else out for my next project. In my quest to instil a bit more order, I’ve started using Hydra, which strikes a nice balance between giving you more structure to organise a project, while not rigidly insisting on it, and I’d highly recommend checking it out yourself.
Continue readingPicture the following: the year is 1923, and it’s a sunny afternoon at a posh garden party in Cambridge. Among the polite chatter, one Muriel Bristol—a psychologist studying the mechanisms by which algae acquire nutrients—mentions she has a preference for tea poured over milk, as opposed to milk poured over tea. In a classic example of women not being able to express even the most insignificant preference without an opinionated man telling them they’re wrong, Ronald A. Fisher, a local statistician (later turned eugenicist who dismissed the notion of smoking cigarettes being dangerous as ‘propaganda’, mind you) decides to put her claim to the test with an experiment. Bristol is given eight cups of tea and asked to classify them as milk first or tea first. Luckily, she correctly identifies all eight of them, and gets to happily continue about her life (presumably until the next time she dares mention a similarly outrageous and consequential opinion like a preferred toothpaste brand or a favourite method for filing papers). Fisher, on the other hand, is incentivized to develop Fisher’s exact test, a statistical significance test used in the analysis of contingency tables.
Continue reading
I will not lie: I often struggle to find a snippet of code that did something in PyRosetta or I spend hours facing a problem caused by something not working as I expect it to. I recently did a tricky project involving RFdiffusion and I kept slipping on the PyRosetta side. So to make future me, others, and ChatGTP5 happy, here are some common operations to make working with PyRosetta for RFdiffusion easier.
Continue readingPython is a prominent language in the ML and scientific computing space, and for good reason. Python is easy-to-learn and readable, and it offers a vast selection of libraries such as NumPy for numerical computation, Pandas for data manipulation, SciPy for scientific computing, TensorFlow, and PyTorch for deep learning, along with RDKit and Open Babel for cheminformatics. It is understandably an appealing choice for developers and researchers alike. However, a closer look at many common Python libraries reveals their foundations in C++.
Revisiting C++ Advantages
Many of Python libraries including TensorFlow, PyTorch, and RDKit are all heavily-reliant on C++. C++ allows developers to manage memory and CPU resources more effectively than Python, making it a good choice when handling large volumes of data at a fast pace. A previous post on this blog discusses C++’s speed, its utility in GPU programming through CUDA, and the complexities of managing its libraries. Despite the steeper learning curve and verbosity compared to Python, the performance benefits of C++ are undeniable, especially in contexts where execution speed and memory management are critical.
Rust: A New Contender for High-Performance Computing
Continue readingDo you use pandas for your data processing/wrangling? If you do, and your code involves any data-heavy steps such as data generation, exploding operations, featurization, etc, then it can quickly become inconvenient to test your code.

Whereas it is easy to say in a paper “Given the HT-Sequential-ITC results, 42 led to 113, a substituted decahydro-2,6-methanocyclopropa[f]indene”, it is frequently rather trickier algorithmically figure out which atoms map to which. In Fragmenstein, for the placement route, for example, a lot goes on behind the scenes, yet for some cases human provided mapping may be required. Here I discuss how to get the mapping from Fragmenstein and what goes on behind the scenes.
Continue readingLast year, I had an opportunity to delve into the world of JAX whilst working at InstaDeep. My first blopig post seems like an ideal time to share some of that knowledge. JAX is an experimental Python library created by Google’s DeepMind for applying accelerated differentiation. JAX can be used to differentiate functions written in NumPy or native Python, just-in-time compile and execute functions on GPUs and TPUs with XLA, and mini-batch repetitious functions with vectorization. Collectively, these qualities place JAX as an ideal candidate for accelerated deep learning research [1].
JAX is inspired by the NumPy API, making usage very familiar for any Python user who has already worked with NumPy [2]. However, unlike NumPy, JAX arrays are immutable; once they are assigned in memory they cannot be changed. As such, JAX includes specific syntax for index manipulation. In the code below, we create a JAX array and change the 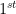
Discovering a library that massively simplifies the exact thing you just did right after you’ve finished doing the thing you needed to do has to be one of the top 14 worst things about writing code. You might think it’s a part of the life we’ve all chosen, but it doesn’t have to be. Beyond the popular libraries you already know lies a treasure trove of under appreciated packages waiting to be wielded. Being the saint I am, I’ve scoured the depths of pypi.org to find some underrated and hopefully useful packages to make your life a little easier.
Continue readingImagine this: you’ve spent days computing intricate analyses, and now it’s time to bring your findings to life with a nice plot. You fire up your cluster job, scripts hum along, and… matplotlib throws an error, demanding an X server it can’t find. Frustration sets in. What a waste of computation! What happened? You just forgot to add the -X to your ssh command, or it may be just that X forwarding is not allowed in your cluster. So you will need to rerun your scripts, once you have modified them to generate a file that you can copy to your local machine rather than plotting it directly.
But wait! Plotext to the rescue! This Python package provides an interface nearly identical to matplotlib, allowing you to seamlessly transition your plotting code without sacrificing functionality. But why choose Plotext over the familiar matplotlib? The key lies in its text-based backend. This means it is just printing characters in your console to generate the plots, making it ideal for cluster environments where X servers are often absent or restricted. What do those plots look like? Here is an example:
Continue reading