
Recently, I have been interested in adding a confidence metric to the predictions made by a machine learning model I have been working on. In this blog post, I will outline a few strategies I have been exploring to do this. Powerful deep learning models like AlphaFold are great, not only for the predictions they make, but they also generate confidence measures to give the user a sense of how much to trust the prediction.
What is confidence?
Confidence is a measure of how well we should expect to do on a task based on what we know about the task, regardless of how well our model actually performs. It is about disentangling performance measure like Accuracy, PR-AUC, and ROC-AUC, from our expectation of the results. The term “calibration” is sometimes used in the literature to refer to confidence, meaning that a “well calibrated” model gives a low score when it is incorrect and a higher score when it is correct. This blog will not focus on how to calibrate a model, but rather on strategies for creating a measure of confidence.
As an example, let’s say we trained a model to detect dogs in an image, but we only had images of pugs to create our training dataset:



Using this data, we build our model and train it. We then stumble upon an extra set of images of bull dogs and we these to evaluate our model:


Great, we seem to do pretty well on the bull dog images so we claim in our report that the model generalises well to other types of dogs and we leave it at that.
Now, another user wants to use our model to scan a database of images for huskies (there are no other types of dogs in this database) and pull out those that contain a dog.


Based on what we know about how are model was developed, would we expect our model to work well on this task? Probably not, huskies and pugs don’t look that similar, unlike the pugs and bull dogs we trained and evaluated our model on. However, our model might still give quite strong predictions to either of our classes “dog”, or “ dog”, regardless if there is a husky in the image. This would make the tool seem unreliable, but in reality, given the right task, our model would do a great job at detecting dogs. If we could have had a confidence prediction that reflected this, it would make the model much more usable and build trust in the predictions.
Here is what our desired outcome might look like:

Model Prediction: No Dog
Desired Confidence: High

Model Prediction: No Dog
Desired Confidence: Low

Model Prediction: Dog
Desired Confidence: Low

Model Prediction: Dog
Desired Confidence: High
Confidence from output probabilities
Maybe the most straight forward, but potentially naïve, approaches we could take is to base our confidence scores off of how strongly our model predicts an input belonging to a given class. In a classifier setting, this means taking the maximum probability assigned by the model to being part of any class:

And then re-scaling this to be between 0 and 1 based on the number of classes (

In the diagram above, we see that the model predicts a probability of 70% of the input belonging to class A and a probability of 30% of belonging to class B:

Meaning that the model is not all that confident that the correct class assignment is class A (0.4 confidence score). If the probabilities had been 99% for class A and 1% for class B then the prediction would have had a confidence score of 0.98, or if the class assignment had been 50/50 then the model would have had a confidence score of 0.
In this example, we have only two classes so we could have formulated our output as a binary classifier where the probability of only one class is considered and the other is implied. In this case, we would take our maximum as 
The approach is quite easy to implement, but it is strongly reliant on having a well calibrated model. If the model strongly predicts classes on real world input (i.e. always either 0 or 1) then the confidence scores will not be particularly meaningful. It is also limited to model architectures where outputs are probabilities and thus would not work for regression tasks.
Monte-Carlo Dropout
The next method, known as Monte-Carlo Dropout, takes a bayesian approach to confidence prediction. Dropout is often an added regularisation step during neural network training. It randomly masks or “drops out” nodes during training so that the model does not become overly reliant on certain embedded features to make predictions and thereby avoids over-fitting. At inference time, it is usually turned off to create deterministic outputs from input data. However, if we leave drop out on during inference and run the input through several times, we can create a distribution of predictions for a given input.
Based on the spread of this distribution (standard deviation), we can get a confidence score. The intuition here is that if the model arrives at the same conclusion using multiple embedded features, the prediction is more robust.

Here, 

This method is also quite easy to implement, especially if dropout is already employed in your model architecture, but it is also reliant on having a somewhat calibrated model (less so than the previous approach).
Lean parameters associated with confidence
The final model-based measure of confidence is to design your machine learning architecture to jointly predict your output value and a confidence score associated with that value.
This is the strategy employed by AlphaFold that we discussed in the introduction. The AlphaFold model predicts both a 3D structure, as well as, a score they call pLDDT (predicted Local Distance Difference Test). LDDT is a performance measure that can be calculated for protein structure predictions based on how closely the prediction recreates the inter-atom distances of the ground truth structure. By estimating the LDDT score, the AlphaFold model bakes in a measure of how confident it is over each region of the protein.
Jumper, J., Evans, R., Pritzel, A. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021). https://doi.org/10.1038/s41586-021-03819-2
In other scenarios, it can be useful to make predictions based on the parameters of a distribution instead of predicting singular values. If the task at hand can be framed in a way that the objective is to predict parameters of a distribution (mean 
Overall, this approach is more involved and takes some thought to be able to set it up in your machine learning models, but it can be add so much robustness to a model.
Data based
The final approach to confidence predictions we will explore is a data-based method that is model agnostic (no not database, data-based).
The inputs to our machine learning models occupy a continuous, multi-dimensional space. We can visualise this in 2D by taking a UMAP projection, like is shown above. When we train our model, we portion out part of this space (not necessarily continuous like is shown) and optimize the model parameters to predict some desired property of these data points. When it comes to inference, the input data points will also sit in this high-dimensional feature space. Some inference data points will be closer to what the model was trained on, some will be further away. We could thus expect that based on how far away from the training data a data point is, the harder it might be for the model to predict. A point that is closer to points in the training data would be easier to predict, a point further away might be harder to predict.
By using the distances between points in our input space, we can create a measure of confidence on how well we expected our model to perform on a given input data point.
In the example above, we could say that the point at distance 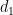
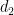

This approach is nice because it is agnostic of the model and task, but it does require some design considerations about how to quantify “close to the training data” and can be computationally expensive if there are a lot of points in the training data. Often, it might be desirable to train another regressor to estimate the distance to the training data in the input space.
Conclusion
Confidence is an important aspect of robust machine learning models. It provides the user with an interpretable result and helps demystify the “black box” that machine learning can be. There are several methods to give confidence to a machine learning model, and it can often take some experimentation to determine the most appropriate strategy for a given task. Hopefully, this blog post gets you thinking about confidence and gives you some new ideas about how to incorporate it into your research.