
One of the fundamental (pitfalls) of machine learning is to ensure that you don’t train on your test set, but what if I told you that you could?

Earlier this week, the ARC Prize 2024 closed for submissions. If you’ve not heard of it, the ARC Prize aims to inspire progress towards AGI. The ARC-AGI benchmark consists of a series of puzzle-like tasks on 2D grids that have proved relatively elusive to machine learning models. One approach that made a large splash on a major social media site right before the submission deadline used test-time training to update the parameters of a large language model as part of the inference procedure (paper).
This is a further example of test-time approaches taking centre stage after OpenAI’s release of the o1 model family.
The idea of continual adaption is critical in many of the problems we work on in OPIG, so I wanted to use this blog post to explain the basics of test-time training.
Enter Test-Time Training
The core paradigm of test-time training (TTT) was proposed at ICML 2020 in the following paper:
The central idea is to find ways of adapting model parameters for specific test example(s), without the need for labels for the test points (otherwise you are, of course, just cheating).
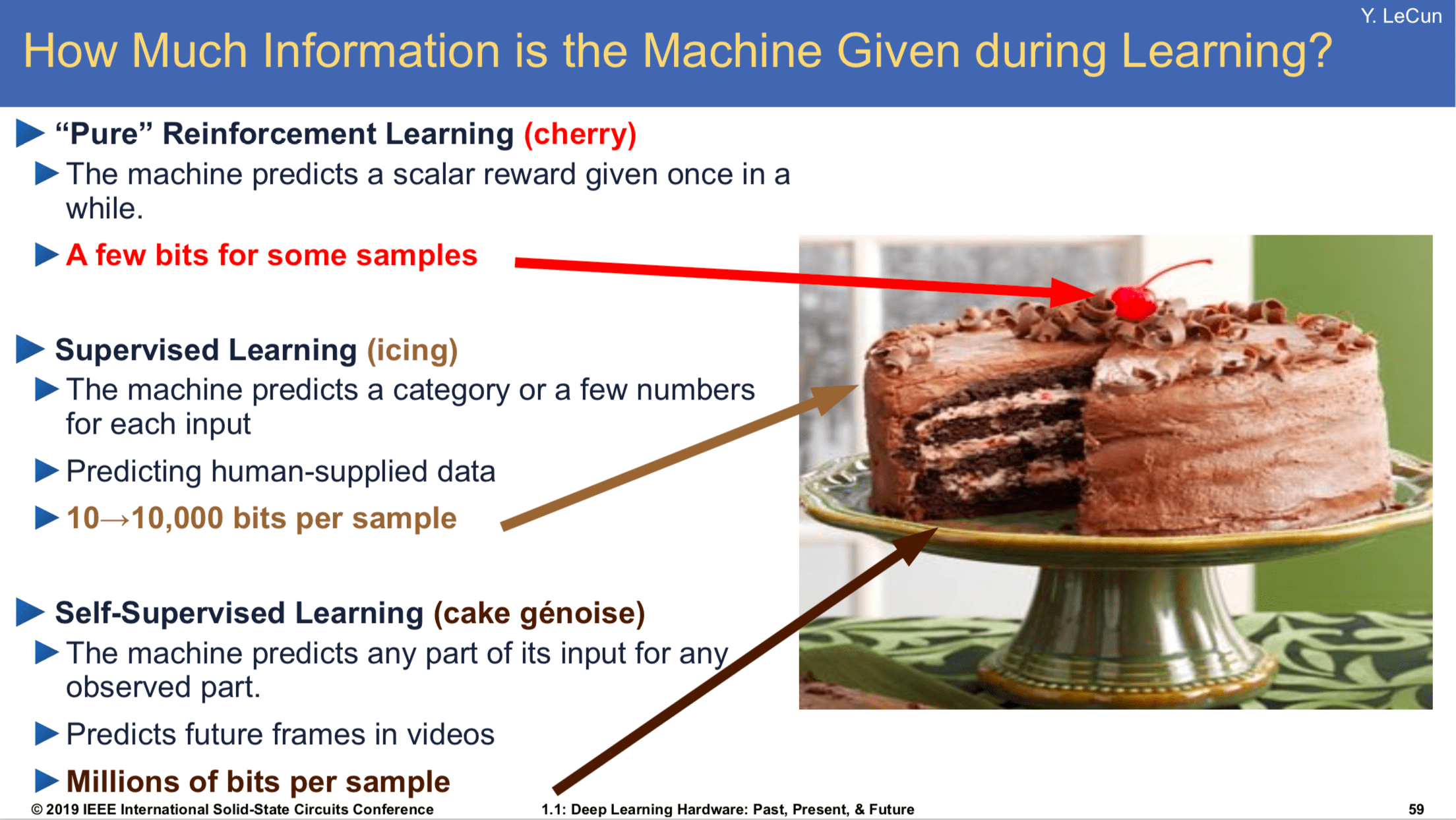
TTT achieves this using self-supervised learning. In self-supervised learning, instead of using labelled data to train a model, you construct a pre-text or auxiliary learning task using only the input data without the label). For example, you could rotate an image and ask the model to predict the angle of rotation. From this, you hope the model learns general-purpose features, which are then useful for solving a downstream prediction task.
At test time, labelled data isn’t available, but you can always construct the self-supervised task for a new input. TTT uses the self-supervised loss at test time to update the model parameters. The intuition is that if you cannot solve the self-supervision task, you don’t understand the sample you’re issuing a prediction for and improving your ability to solve the self-supervision will help this.
While this is generally applicable, the authors first explored it specifically in the context of distribution shifts, where existing techniques such as adversarial robustness and domain adaption required you to anticipate the type of distributional shift that might occur. In contrast, TTT makes no assumptions about what shifts are possible but tries to learn them directly at test time.
Personally, I think we’re going to see continued improvements in the techniques available at test time. However, we can only learn so much from a single unlabelled test point, so this feels more like the icing on the cake. However, what’s a cake without icing?
{kind=link}
If you’re interested in learning more about test-time training, I encourage you to take a look at this project website.