The article An Exponential Family of Probability Distributions for Directed Graphs, published by Holland and Leinhardt (1981), set the foundation for the now known exponential random graph models (ERGM) or p* models, which model jointly the whole adjacency matrix (or graph) 

The article is mainly focused on directed graphs (although the theory can be extended to undirected graphs). Two main effects or patterns are considered in the article: Reciprocity, which relates to appearance of symmetric interactions (

and, the Differential attractiveness of each node in the graph, which relates to the amount of interactions each node “receives” (in-degree) and the amount of interactions that each node “produces” (out-degree) (the Figure below illustrates the differential attractiveness of two groups of nodes).
 The model of Holland and Leinhardt (1981), called p1 model, that considers jointly the reciprocity of the graph and the differential attractiveness of each node is:
The model of Holland and Leinhardt (1981), called p1 model, that considers jointly the reciprocity of the graph and the differential attractiveness of each node is:
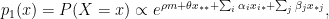
where 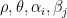

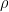


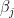
The values 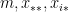
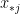
Taking 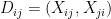

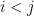
To better understand the model, let’s review its derivation:
Consider the pairs 


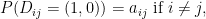
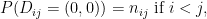
where 
Hence leading

where 
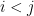
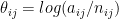
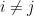
It can be seen that the parameters 

and
![exp(\rho_{ij})=[ P(X_{ij}=1|X_{ji}=1)/P(X_{ij}=1|X_{ji}=0) ]/[ P(X_{ij}=1|X_{ji}=0) / P(X_{ij}=0|X_{ji}=0) ],](https://s0.wp.com/latex.php?latex=exp%28%5Crho_%7Bij%7D%29%3D%5B+P%28X_%7Bij%7D%3D1%7CX_%7Bji%7D%3D1%29%2FP%28X_%7Bij%7D%3D1%7CX_%7Bji%7D%3D0%29+%5D%2F%5B+P%28X_%7Bij%7D%3D1%7CX_%7Bji%7D%3D0%29+%2F+P%28X_%7Bij%7D%3D0%7CX_%7Bji%7D%3D0%29+%5D%2C+&bg=ffffff&fg=000&s=0&c=20201002)

Now, if we consider the following restrictions:


With some algebra we get the proposed form of the model